
AI Image Captioning Tool
Project Overview
Objective:
The objective of this project was to develop an AI-powered image captioning tool that converts visual data into descriptive text. The solution demonstrates practical applications in accessibility, SEO, and workflow automation by leveraging state-of-the-art machine learning models and an intuitive user interface.
My Role:
I designed and implemented the project end-to-end, from selecting the AI model to building the interface. My responsibilities included integrating Hugging Face’s BLIP model, creating the interactive application with Gradio, and tailoring the solution to real-world business scenarios, such as improving media workflows and enhancing accessibility.
Technology:
The project was built using Python as the core programming language. It integrates Hugging Face Transformers for model access, specifically the BLIP (Bootstrapping Language-Image Pre-training) model for image-to-text captioning. The interactive interface was developed with Gradio, enabling simple deployment and user interaction. Supporting libraries included PyTorch for deep learning operations and standard Python packages for application functionality.
Concept to Completion

Design Process
I selected the BLIP model, integrated it with Hugging Face Transformers, and built a simple Gradio interface to deliver a functional, user-friendly prototype.

Challenges
One challenge was ensuring smooth model integration with Gradio while maintaining efficiency. Another was aligning technical outputs with practical business use cases.

Outcome
The final application successfully generated accurate image captions with a simple, user-friendly interface. It demonstrated clear value for accessibility, SEO, and workflow optimization.

Reflection
This project reinforced the importance of combining technical execution with business impact. It also highlighted how adaptable AI tools can be when applied to real-world challenges.
Demo Walkthrough
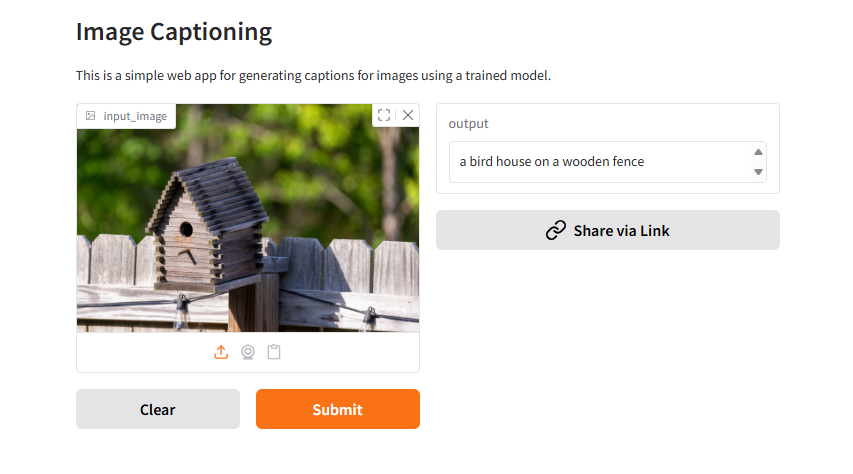
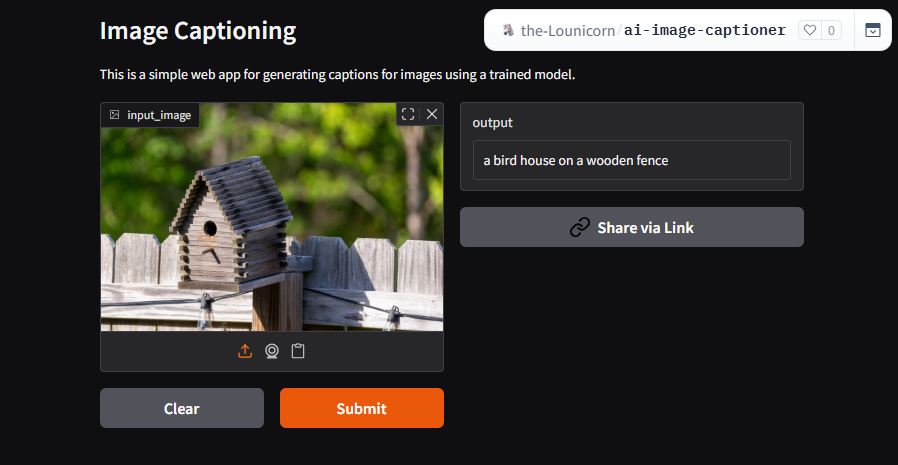
This section highlights the AI image captioning tool in action. See how users can upload images, view automatically generated captions, and interact with the Gradio interface for a seamless experience.
System Architecture
The AI image captioning tool integrates several components to convert images into descriptive text. Images are uploaded through the Gradio interface, which communicates with the BLIP model via Hugging Face Transformers. The model, built on PyTorch, processes the images and generates captions, which are then displayed in the interface for review or further use. This modular architecture ensures scalability, efficiency, and easy adaptation for different business scenarios.

Use Cases
This AI Image Captioning Tool is designed to transform visual content into meaningful, machine-readable descriptions. Here are key ways it can be applied across accessibility, marketing, research, and global content management.

Accessibility Made Easy
Ensure images are understandable for visually impaired users, improving inclusivity and compliance with accessibility standards.

Multilingual Reach
Creates accurate, context-aware captions in multiple languages, enabling content to engage diverse global audiences efficiently.

Research & Education Support
Provides detailed descriptions and categorization for large image datasets, streamlining analysis and enhancing learning materials.

Social Media & Marketing Automation
Generates engaging captions instantly for social posts, ads, or campaigns, saving time and maintaining a consistent brand voice.

SEO & Content Discovery
Automatically produces meaningful, machine-readable captions that help search engines index images, boosting visibility and traffic.
